
Reports
The process for generating reports is the same for the initial report and the remediation report. The difference is the scan that you select for the report.
Generating Reports
In CipherTrust Data Discovery and Classification, click Add Report to initiate the wizard:
Insert a Name and Description for the report you are creating.
In the Configure Content section, select which remediation scans you want to include in the report. You can select a scan that contains the Latest Results, or results from a previous scan. Default selection is Latest Execution. Click Save to generate the report.
After generating the report, it is automatically opened and saved in the Reports list.
Analyzing Reports
The Scans report provides insights related to the data found by the scan selected in the selected data store. That data was analyzed and classified based on the profile included in the scan.
Example
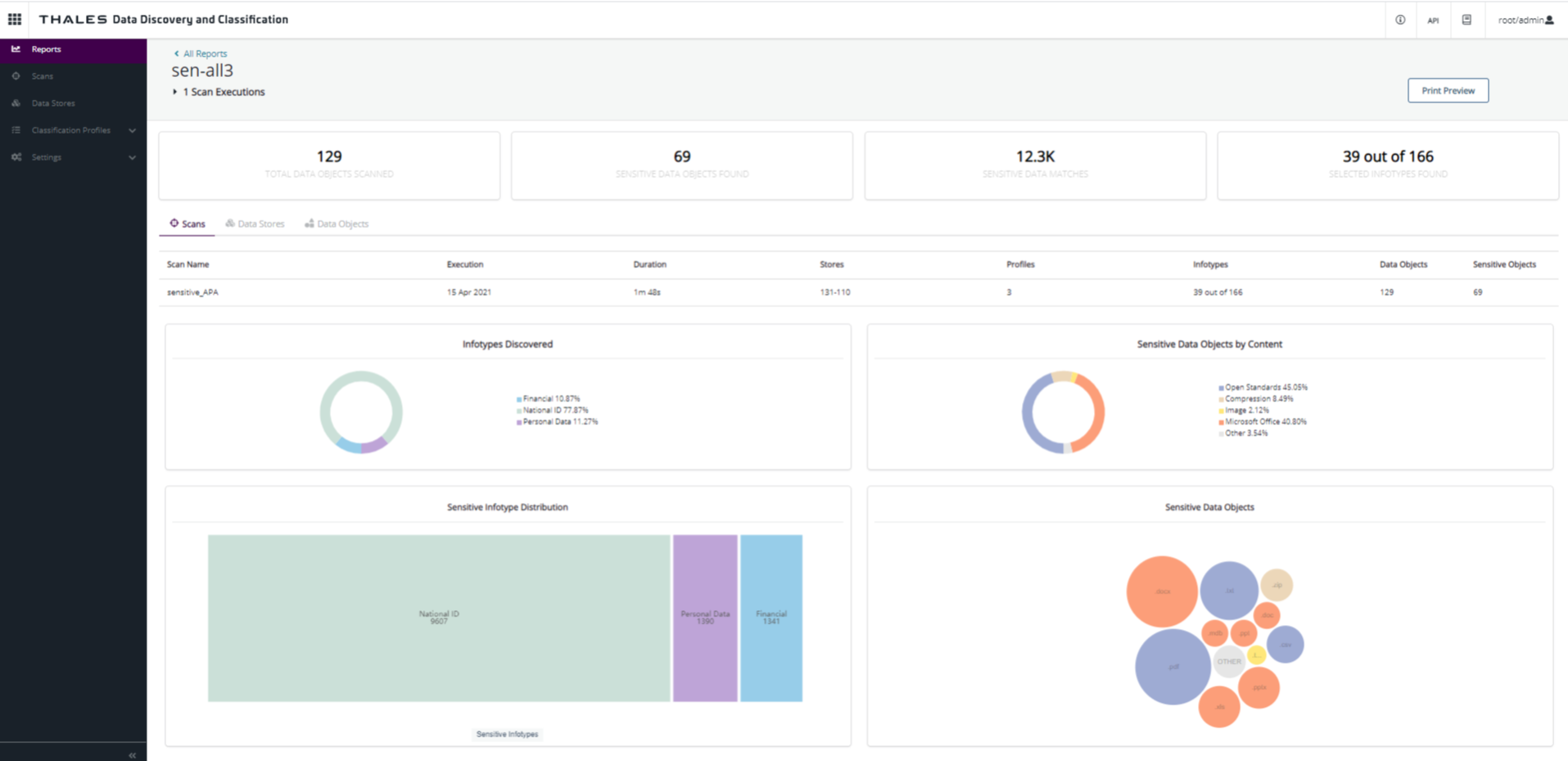
In the following example, using the PCI profile on a the Windows server data store, the scan searched for PCI information.
In the following report, you can see that the four infocards provide a summary from the scan results:
129 data objects (specifically: files) were scanned in the target
69 files from the 129 scanned contained sensitive information
12.3K matches where found in the files
39 out of 166 selected infotypes were found and classified.
Scans Tab
The Scans tab offers a summary of insights related with the selected scan:
A table with the scan information (Scan name, Execution, Duration, Stores, Profiles, Infotypes, Data Objects, and Sensitive Objects).
A pie chart with the category of sensitive information classified
A tree map where you can navigate through the discovered infotypes and the number of matches for each one
A pie chart and bubbles map with the type and extension of files where the sensitive information was found: pdf, txt, docx, png.
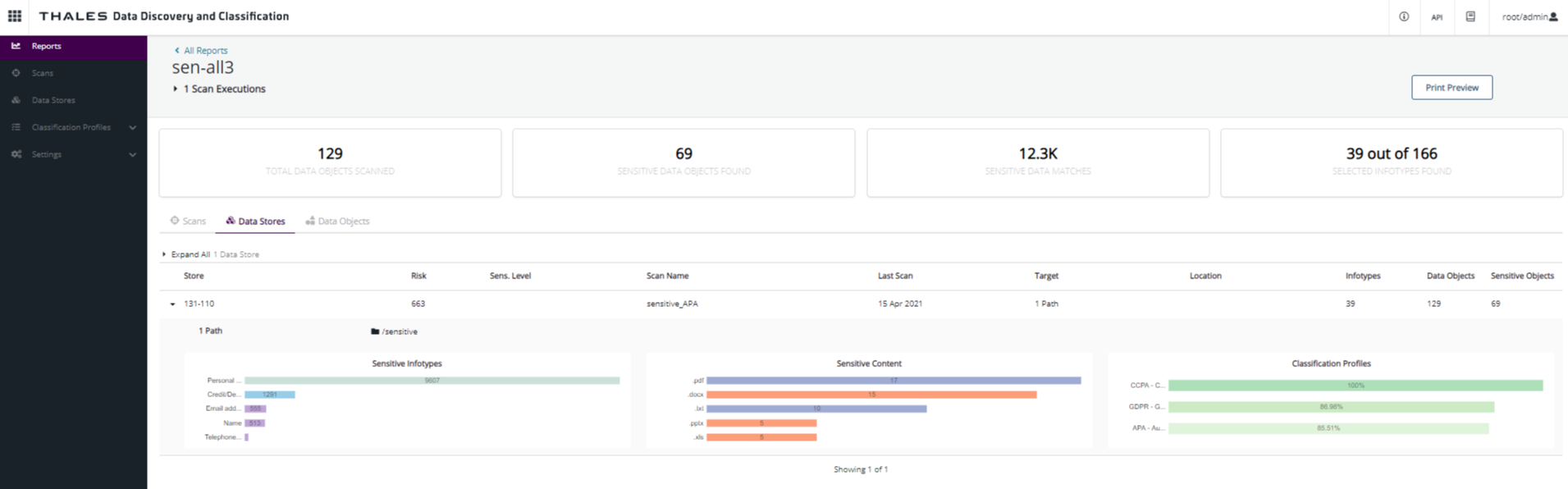
Data Stores Tab
The Data Stores information is included in the scans report. In this case, only one data store was selected and included in the report.
The more relevant information from the data store is presented in the table below. The row is expanded to show the three charts that add more detail about the sensitive data located on it.
Data Objects Tab
The Data Objects tab provides more granularity for the results of the scan. It provides a list of the top 1000 Data Objects containing sensitive information.
For the report below, the Data Objects are only files. No databases were scanned. The data objects are sorted by order of risk, so it is presented at the top of the files list, indicating that it is a higher risk to the organization.
From the following image, there are 69 files containing sensitive information and all of them are located in D:\sensitive. As a result, this folder will be the targets for the next section, where the folder is encrypted.
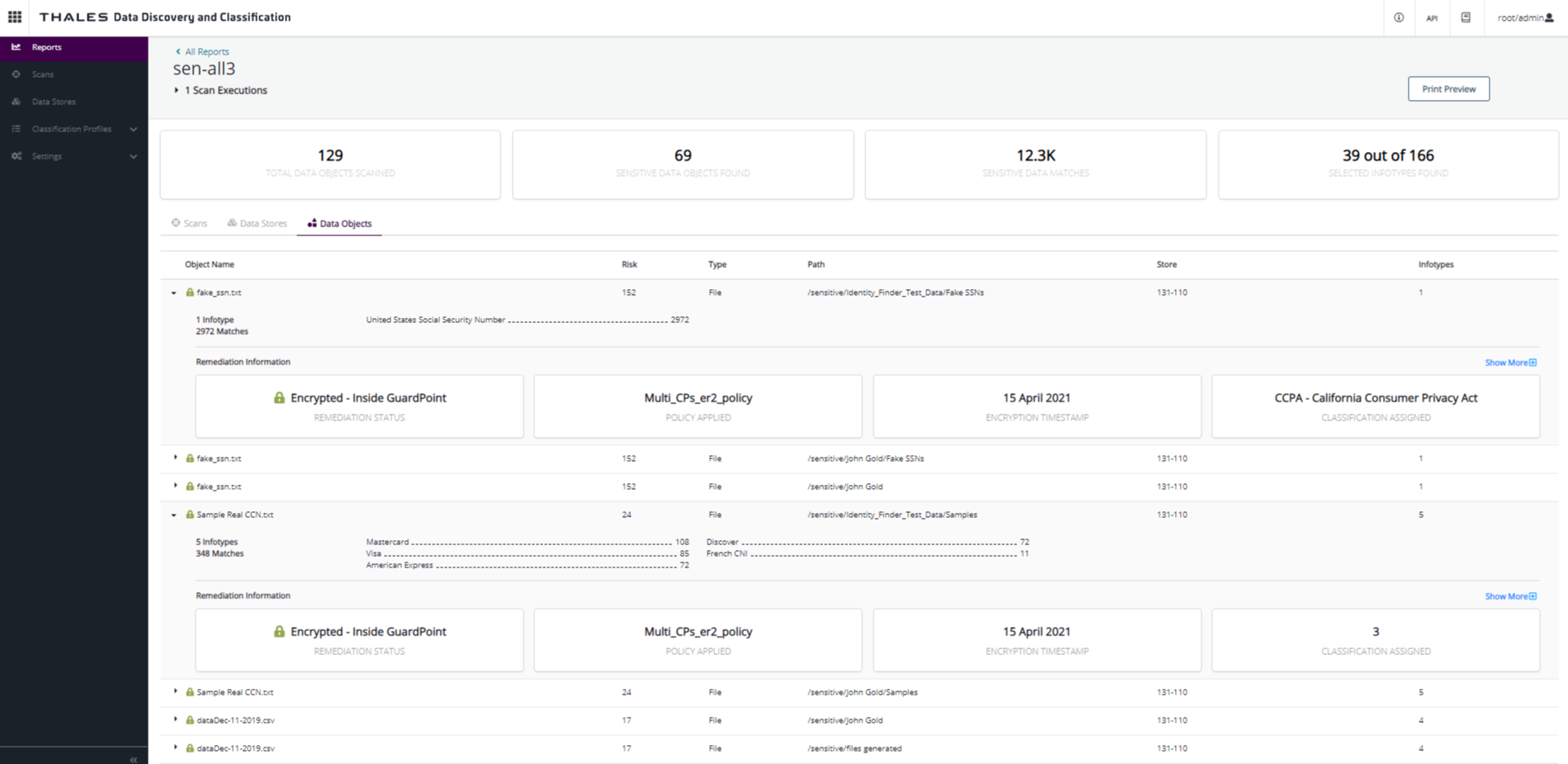
As you can see in the graphic, you can expand the row of any Data object and see all of the infotypes and matches inside this file. In the following image, the information from the file with highest risk displays. You can see that there are two different infotypes inside this file and 66180 matches, raising the risk of this file to 6626. It contains approximately 32882 visa and 33298 mastercard numbers.

CipherTrust Data Discovery and Classification performed discovery and classification on one of the data stores. The report shows what sensitive information is contained in the files inside of the data store, where it is located, and the risk that it implies to your organization.
The next step is to mitigate that risk by protecting the sensitive information according to the criticality and impact it could have if any of it was disclosed. Using CipherTrust Transparent Encryption, encrypt the folders where the sensitive information was found.
After the second scan finishes, run a second report on the remediated data.
Note
After Remediation, the Risk Score of each Data Object is reduced by half.
Risk Score
To calculate the risk formula, CipherTrust Data Discovery and Classification combines all of the risk-related parameters that influence the risk for an organization and for its data stores. This includes the Data Object risk and the Data Store risk. It then multiplies each parameter by a risk factor so it can increase/ decrease the priority of each parameter.
In future versions, a system administrator will be able to alter the risk score formula factor value to increase/decrease or disable a specific parameter impact.
The final risk score for each object in the system is determined by calculating the Data Object with the highest risk score, and then dividing this number by 3. The lower the score, the better. The higher the score, the higher the risk.
Note
For a file system, a Data Object is a file. For a database, a Data Object is a table.
Data Object Risk
Data Object risk is defined by evaluating the following parameters:
Sensitivity Level
This is determined by the classification profile sensitivity level. Points are assessed based on the order of the sensitivity levels. The lowest sensitivity level is 1. If multiple profiles include the same Data Object, then the risk calculation uses the highest sensitivity level for the Data Object.
Regulation
Determines if the Data Object complies with the regulations specified by the classification profile.
Infotypes
Number of infotypes found in the Data Object.
Items
Number of items found in the Data Object.
Mismatched Sensitivity Level
A Data Object that is classified by a classification profile with a higher sensitivity level then a Data Store.
Data Store Risk
Data Store risk is defined by evaluating:
Average Risk
This risk calculation is based on the total sum of risk stemming from all Data Objects on a Data Store, divided by the number of sensitive Data Objects.
Highest Risk
Displays the risk for the highest score for a specific Data Object.
Infrastructure Risk
Risk score is based on the following:
- If CipherTrust Intelligent Protection cannot perform remediation on a Data Store it receives a risk point.
- If the Data Store is not scanned every week it receives a risk point.