
Managing Scans
You manage scans through the Scans page, which is accessed by clicking the Scans link in the Data Discovery sidebar on the left.
From the Scans page you can:
View all currently availablae scans. See Viewing Scans.
Create a new scan. See Adding Scans.
Run a scan manually. See Running Scans.
Delete a scan. See Removing Scans.
Modify an existing scan. See Editing Scans.
Create a new scan from an existing one. See Duplicating Scans.
Viewing Scans
The list view of the Scans page shows the number of:
- Scans with the number of executed and unexecuted scans.
- Executed scans with the number of scans containing sensitive and non-sensitive data.
- Scanned data objects with the number of sensitive and other data objects.
Click the refresh button to refresh the displayed information.
The list view of the Scans page shows the following details:
| Item | Description |
|---|---|
| Name | Name of the scan. |
| Profiles | Number of classification profiles. |
| Schedule | Schedule of the scan. |
| Last Scan | Time when the scan last ran. |
| Duration | Time taken to complete the run. |
| Status | Status of the scan. For more information, see Scan Statuses. |
Tip
If you are planning to perform a CipherTrust Manager upgrade, make sure that you do not have scans in progress.
Use the Search text box to filter scans. Search results display scans that contain specified text in their names.
By default, scans are listed in ascending alphabetic order of their names.
Scans can be sorted by their name, last scan time, duration, and status.
Adding Scans
To add a scan, navigate to the Scans screen (Data Discovery > Scans). Click the +Add Scan button to open the Add Scan wizard.
In the wizard, you have to go over these configuration steps for each scan that you add:
General Info - Name the scan and give a short description.
Select Data Stores - Select which data stores will be scanned.
Add Targets - Narrow down the scan scope by selecting specific scan targets.
Select Profiles - Choose which Classification Profile you want to scan for.
Apply Filters - Add a list of rules to filter some targets when the scan is launched.
Schedule Scan - Configure when you want your scan to run.
General Info
In the General Info screen, the wizard asks you to specify a unique name for the scan and to give it a short description:
Name - The name must be longer than two characters and up to 64 characters.
Description - optional description of up to 250 characters.
Click Next to move on to the Select Data Stores screen.
Select Data Stores
The Select Data Stores screen lists all data stores in tabular form. By default, no data stores are selected. The table has three columns:
Data Store Name: Lists available data stores (with their number).
Type: The type of the data store, such as Local Storage, Network Share, etc.
Agent: Displays the Agent that is connected to that data store. In this column, you can also see if the Agent is ready (that is, if the data store is ready).
To select a data store to scan:
Search for the desired data stores by specifying the search criteria in the Search box. The search results will be displayed in the table under it.
Select a data store for the scan by selecting the corresponding check box. Similarly, select multiple data stores, if needed.
Tip
Use the Selected only toggle switch to display only the selected data stores or all data stores (if the switch is 'off' all data sources are displayed).
Click Next to move on to the Add Targets screen.
Add Targets
In the Add Targets screen you can review a list of the data stores that you selected for the scan. By default, the scan will scan the entire data store, and this wizard step allows you to narrow down the scan scope by selecting specific targets for your selected data stores. The Add Targets screen is divided into three columns:
Data Store: The list of selected data stores.
Targets: Any selected specific target for the listed data store. "Full DS" indicates that no specific target has been selected, that is, the entire data store will be scanned. If you have added a scan target for the data store, it will be listed after you expand the data store row (by clicking the arrow button next to the data store name, on the left).
Add Target Path: In this field you can type in a specific target and add it to the scan parameters. Scanning of this data store will be limited to the added target only.
- Any scan target that you add must be valid, otherwise the scan will fail. For more information on what a valid scan target is, see Target Format Limitations.
- For performance sake, try running smaller scans and then generate a report in which you aggregate them. You may schedule a different scan per Data Store and/or per Classification Profile and/or subpaths (such as folders and tables) in the original scan path.
- You can scan emails in a Gmail label if you move the emails to the label - otherwise, they will be kept in your inbox. For the default system labels, Gmail creates some folders that do not match the label name. Please refer to the Gmail documentation to learn the right path to scan a particular system label.
!!! tip * In the case of a Sharepoint Server data store with an API passwords file configured, you have to use an empty target path.
- Any scan target that you add must be valid, otherwise the scan will fail. For more information on what a valid scan target is, see Target Format Limitations.
To add a scan target for a selected data store:
Type your scan target in the Add Target Path field.
- Click the Apply button on the right to add the target.
Repeat this to add more scan targets for that data store, if needed.
To remove a scan target for a selected data store:
Click the arrow button next to the data store name for which you want to remove a scan target.
Click the Remove link on the right of the scan target to remove it.
Use the Enable Remediation toggle switch to enable remediation for the selected target.
Note
Remediation is currently only supported on local storage type data stores. In case of other types of data stores the Enable Remediation switch will not be displayed at all.
The Enable Remediation switch is only active when remediation is supported and properly configured on the data store where you want to enable remediation. Otherwise, you will not be able to switch it on. The various messages displayed on mouse over on the inactive switch provide you the information on the reason for it being inactive, such as:
- "No CTE Agent installed in the host" - There is no CTE Agent installed on the data store. Install a CTE Agent and configure a GuardPoint for the target.
- "Outside of a GuardPoint" - A CTE Agent is installed but there is no GuardPoint configured for the target. Go to the Transparent Encryption application and configure a GuardPoint for the data store or target.
- "CTE Agent or GuardPoint disabled" - In this case, the CTE Agent and/or the GuardPoint exist but are disabled.
For more information on the CTE Agent and configuring GuardPoints, refer to the "Managing GuardPoints" topic on the CipherTrust Platform Documentation Portal.
Additionally, this message appears after switching off the Enable Remediation toggle for a previously enabled target:
"Previous encryption is kept. Remediation won't be updated."
For detailed information on how DDC uses remediation, refer to Remediation.
To move on to the Select Profiles screen, click Next.
Tip
Make sure that you do not have nested target paths in a scan for the same data store. This can affect the performance of the scan and you can get duplicated data in the reports.
Select Profiles
The Select Profiles screen lists all classification profiles in tabular form. By default, no profiles are selected. The table has three columns:
Classification Profile Name: Lists available profiles. Items marked with a letter "T" are predefined classification profile templates. For more information about these templates, see "Classification Profile Templates". The other items are custom classification profiles.
Infotypes: Displays the number of information types associated with the profile.
Sensitivity: Displays the sensitivity level assigned to this classification profile. See "Sensitivity Levels" for more information.
To select a classification profile for the scan:
Search for the desired profiles by specifying the search criteria in the search box. The search results are displayed in the table under it.
Select profiles for the scan by selecting the check boxes corresponding to desired profiles.
Tip
Use the Selected only toggle switch to display only the selected classification profiles or all classification profiles (if the switch is 'off' all classification profiles are displayed).
Click Next to move on to the Schedule screen.
Apply Filters
In the Apply Filters screen you can add a list of rules to filter some targets when the scan is launched. By default, there are no filters applied, and in this step you can add specific rules which affect the data stores selected and their targets (if you specified any). You can configure as many filters as you want.
Click the Select Filter menu to expand it. The menu shows you the filters as follows:
Exclude location by prefix
This filter excludes search locations with paths that begin with a given string. It can be used to exclude entire directory trees. Example of such a filter: c:\windows\system32Exclude location by suffix
This filter excludes search locations with paths that end with a given string. For example, entering led.jnl, excludes files and folders such as canceled.jnl, totaled.jnl.Exclude locations by expression
This filter excludes search locations by expression. Wildcards '*' and '?' can be used to form expressions for this filter. For example, *data.txt excludes files that end by "data.txt" in any path.Include locations modified recently
Use this filter to include search locations modified within a given number of days from the current date. For example, enter 14 to display files & folders that have been modified not more than 14 days before the current date.Exclude locations greater than file size
This filter excludes files that are larger than a given file size (in MB).Include locations within modification date
Use this filter to include search locations modified within a given range of dates. Files and folders that fall outside of the range set by the selected start and end date are not scanned.
For each new filter added click Apply to save and apply its rules.
Click Next to move on to the Schedule screen.
Note
Filters are case insensitive. That is to say, if you have two directories, "TEST" and "test" and apply the filter */test both directories will be excluded as a result. The same goes for filenames.
Depending on the type of data store, some considerations should be taken into account. For more info, see Scan Filter Usage.
Schedule Scan
Scans can be run either manually or automatically at a scheduled time. To configure this:
In the Schedule screen select the frequency with which you want the scan to run. The options are:
Manual: Select to run the scan manually. This is the default setting. In this case the scan will be run whenever you manually launch it from the Scans screen. For more information about running a scan manually, see Running Scans.
Automatic Scan Pause - Use this switch to schedule the time when a scan will pause. For example, you should pause all scans (by using the automatic scan pause) during working hours so they do not affect production servers. Next, use the Time Zone and Select days and time controls to set the day(s) and time when the scan should pause.
Run Now - If you select this checkbox, the scan will be run just once after the scan is added successfully.
Scheduled: Select to specify a schedule for the run. The scan will be run automatically on the specified schedule. When Scheduled is selected, the following fields appear on the screen:
Increment: Select the increment pattern of the run. This is a mandatory field. The options are Daily, Weekly, and Monthly. By default, Daily is selected.
Every: Specify when the run should repeat. This is a mandatory field.
For example, if Daily is selected as Increment, enter 2 to run the scan once every two days. If Weekly is selected as Increment, enter 2 to run the scan once every two weeks. Similarly, if Monthly is selected as Increment, enter 2 to run the scan once every two months.
Time: Specify the time when the run should start. This is a mandatory field. Specify the time in 12-hour format.
Time Zone: Select a time zone form the drop-down list.
Starting: Specify the day when the schedule should start. This is a mandatory field. By default, Today is selected. To specify a particular start date, select On this date, click the calendar icon, and select the date.
Ending: Specify the day when the schedule should end. This is a mandatory field. By default, No End is selected. To specify a particular end date, select On this date, click the calendar icon, and select the date.
Automatic Scan Pause - Use this switch to schedule the time when a scan will pause. For example, you should pause all scans (by using the automatic scan pause) during working hours so they do not affect production servers. Next, use the Time Zone and Select days and time controls to set the day(s) and time when the scan should pause.
Note
A scan cannot run unless there is an identified Agent for every data store included in the scan. If it fails to run, check the status of different data stores included in the scan.
Click Save to complete adding the scan.
As a result, the newly created scan appears on the Scans page. By default, scans are displayed in alphabetic order by name. Depending on the number of entries per page, you might need to navigate to other pages to view the newly created scan. By default, the Status of a newly created scan is Unscanned.
Note
If your CM system clock does not match the Agent's system clock, your scans will not run as scheduled, so it is highly recommended to set up a NTP server to synchronize the clocks. This can be achieved in CM through the Admin Settings -> System -> NTP. For details, refer to the Thales CipherTrust Manager Administrator Guide.
Target Format Limitations
What is a valid scan target depends on the data store type. In this section we give you a few tips to have in mind.
Database data sources
When adding scan targets for database data sources (IBM DB, Oracle, andMS-SQL):
Note that table names are case sensitive but schema names are not case sensitive.
Oracle data stores accept only tables as scan targets.
IBM DB and MS-SQL data stores accept schemas or tables as scan targets.
For Oracle and IBM DB2 it is recommended to set the path in uppercase if the database is configured as case-insensitive.
Cloud data stores
For Hadoop and AWS S3 type data stores, you can configure a scan to use a specific file as a scan target.
For Azure Blob type data stores you can only specify containers as scan targets.
Big Data stores
Due to known Teradata limitations Data Discovery cannot scan the following Teradata internal databases:
- SYSJDBC
- All
- TD_SYSXML
- DBC
- TDStats
- TD_SYSGPL
- PUBLIC
- SQLJ
- SYSBAR
- Default
- SYSLIB
- TD_SYSFNLIB
- LockLogShredder
- tdwm
- TDPUSER
- External_AP
- EXTUSER
- dbcmngr
- SystemFe
- SysAdmin
- TDMaps
- TDQCD
- Crashdumps
- Sys_Calendar
- viewpoint
- TD_SERVER_DB
- console
- SYSUDTLIB
- SYSUIF
- SYSSPATIAL
Office 365 Sharepoint Online data stores
In case of Office 365 Sharepoint Online type data stores, you need to understand how resources in a Office 365 Sharepoint Online storage are organized and managed.
For sites, /:site gets appended whenever a root site collection, non-root site collection and sub-site locations are added. The location can be probed without explicitly adding /:site in the path field.
Every site collection has List and File folders and to access their content /:site/:list and /:site/:file should be used respectively.
Use the following formats to create your desired scan target paths:
All lists
<web_application_url>/<site_collection>/:site/:list
e.g.:
http://xxxxxx/testdata/:site/:list
A list
<web_application_url>/<site_collection>/:site/:list/<list>
e.g.:
http://xxxxxx/sites/test/:site/:list/Site Pages
All files
<web_application_url>/<site_collection>/:site/:file
e.g.:
http://xxxxxx/testdata/:site/:file
A folder
<web_application_url>/<site_collection>/:site/:file/<folder>
e.g.:
http://xxxxxx/testdata/:site/:file/SharedDocuments
A file
<web_application_url>/<site_collection>/:site/:file/<file>
e.g.:
http://xxxxxx/sites/test/subsite1/:site/:file/EHIC.rtf
A file in a folder
<web_application_url>/<site_collection>/:site/:file/<folder>/<file>
e.g.:
http://xxxxxx/testdata/:site/:file/Shared Documents/cards/Amex.odt
or
http://xxxxxx/testdata/:site/:file/Shared Documents/2001P11.pdf
Running Scans
To run a scan manually:
Navigate to the Scans screen (Data Discovery > Scans).
Search for the scan to run.
Use the Search text box to filter scans. Search results display scans that contain specified text in their names.
By default, scans are listed in ascending alphabetic order of their names.Tip
Scans can be sorted by their name, last scan time, duration, and status.
Move the mouse pointer to the row that contains the scan. The Run Now button appears. This button disappears as soon as the mouse pointer is moved out of the row.
Click Run Now.
As soon as the scan is initiated, its status changes to Pending, then the status changes to Processing. If the automatic scan pause is configured for the scan and you are running it within the set time window, the status of that scan will be Autopaused throughout the duration of the time window. After that, the scan is resumed. For more details on the scan auto pause feature, refer to the information in Schedule Scan.
Scan Statuses
The status of the scan changes in the sequence: Unscanned > Validating > Pending > Running now / Paused / Stopped > Processing > Completed / Failed.
The progress of the scan (i.e. its current status) is displayed in the Status column in the Scans screen. See the table below for information on the possible statuses:
| Status | Description |
|---|---|
| Unscanned | By default, the Status of a newly created scan is Unscanned. |
| Validating | Checking if all the data stores are ready. |
| Pending | Scan is pending and the linked data stores are being contacted. Depending on factors such as the network connectivity, this stage may: • Complete in a flash. You may not see it on the Scans page. • Remain for some time in this state. |
| Running now, Paused, Stopped | Scan is running, is paused, or is stopped. See Scan Progress below for more information. |
| Autopaused | Scan is paused as a result of automatic scan pause. |
| Processing | Scan is processing the collected data. |
| Classifying | Sensitive data objects found during the scan are being classified prior to being remediated. |
| Reclassification Failed | The reclassification process failed so no data is remediated. |
| Completed, Failed | Scan run is successful or has failed. |
Scan progress: Additionally for ongoing scans, their progress in percentage is displayed in the form of a progress bar accompanied by a numeric percentage value. This information is available for the "Running now" and "Paused" scan statuses.
Potential Problems When Running Scans
Ready/Not Ready data store: A scan cannot run unless there is an identified Agent for every data store included in the scan. Such a data store has the status Ready. A scan that has at least one data store that is Not Ready will fail to run, and display an error. If more than one data stores associated with a scan are Not Ready the system will fail on the first scanned data store that is Not Ready and will not check the remaining data stores.
Disabled/Enabled data store: You can manually deactivate a data store. Such a data store has a status Disabled and it will not be scanned. A scan that has several data stores associated will still run (without an error) even if one or more data stores are Disabled as long as at least one data store is enabled, but it will only scan the enabled data stores. A scan with all data stores Disabled will not run at all.
Hadoop file access rights: You get a "data store path not accessible" error when scanning a Hadoop data store that has a Hadoop file configured as its scan target, if you do not have access rights to that file.
IBM, Oracle and MS-SQL - empty table or schema: You get a "table or schema not accessible" error when scanning an empty table or schema.
IBM, Oracle y MS-SQL - case sensitive table name: In these data stores database schema names are not case sensitive, but table names are case sensitive.
Scans that identify more than 500.000 Sensitive Data Objects may fail with a generic error: In such cases, we recommend splitting the scan into smaller scans.
Scanning a Gmail label did not find any results: - You can scan emails in a Gmail label if you move the emails to the label - otherwise, they will be kept in your inbox. For the default system labels, Gmail creates some folders that do not match the label name. Please refer to the Gmail documentation to learn the right path to scan a particular system label.
Editing Scans
To edit a scan:
Log on to the DDC console.
Open the Data Discovery application.
In the left pane, click Scans. The Scans page is displayed. This page lists available scans.
Search for the scan to edit.
Use the Search text box to filter scans. Search results display scans that contain specified text in their names.
By default, scans are listed in ascending alphabetic order of their names.
Scans can be sorted by their name, last scan time, duration, and status.
Click the overflow icon (
 ) corresponding to the desired scan. A shortcut menu appears.
) corresponding to the desired scan. A shortcut menu appears.Click View/Edit from the shortcut menu.
The selected scan is displayed, with its configuration settings distributed over these sections (which are exactly the same as the steps of the Add Scan wizard):
GENERAL
DATA STORES
TARGETS
CLASSIFICATION PROFILES
APPLY FILTERS
SCHEDULE
Click Expand All to expand all sections or a plus button (+) in the section in which you want to edit the scan configuration to expand just that section. For information on the available settings, refer to "Adding Scans".
Make the desired changes and click Save Changes to save the changes.
When you edit a scheduled scan that was disabled, it gets automatically enabled.
When you edit a scan, you must run it again to see the corresponding report.
Removing Scans
In the Scans screen, use the Search text box to filter scans and search for the scan that you want to remove.
Click the overflow icon (
) corresponding to the desired scan. An overflow menu is displayed, with the Remove options available.Note
The Remove option is not always available in the menu, only if a scan is Failed, Completed, Stopped, or Disabled.
Click Remove in the menu. As a result, a warning message "Remove Scan? Are you sure you want to remove this scan?" is displayed.
Click the Remove button in the warning message window to confirm the removal of the selected scan.
Reclassifying Scans
Reclassifying scans allows you to remediate scans that were already executed, successfully completed, and where remediation was not previously applied without the need to run them again.
Note
This feature is only valid for scans run in CM 2.7 and above.
In the Scans screen, when remediation is enabled for a target inside a scan, click the overflow button. The Reclassify option is available.
Click Reclassify in the menu. As a result the scan will run the classification process and change the scan status to "Classifying".
Tip
Reports containing a scan where reclassification was launched, must be generated by using the Generate option if you are to see the updated results.
Using Optical Character Recognition in Scans
DDC features Optical Character Recognition (OCR) on a number of image file formats. The formats that can be recognized are JPG / JPEG, BMP, PNG, GIF, TIFF, and PDF that contains any of these image formats.
Note
OCR scans will usually have a lower accuracy than raw text data scans. They may not always recognize all characters in an image due to multiple factors such as poor image quality, unusual fonts, and complex layouts. This may cause unexpected data object matches.
OCR Caching
The DDC scanning engine caches the result of OCR on an image within a scan, which can then be reused if the same image is later found in multiple locations within the same scan, for example, when scanning data sources like email in which identical images frequently occur in different email messages.
OCR Limitations
The OCR mechanism employed by DDC has the following limitations:
It cannot detect handwritten information - only typed or printed characters.
It does not find information stored in screenshots or images of lower quality. The images you scan with OCR enabled must have a minimum resolution of 150 dpi (300dpi or higher is recommended).
At the same time, the accuracy of scans involving OCR will depend on:
The quality of the image. Any noise in the image such as scanner marks, lines or soft color tones, dust from scanned images, etc.
The format of the image. Some image formats will result in better detection rates (lossless vs lossy compression).
Font face, font size and context stored in the image. Fonts within scanned images must be at least 10pt in size. Fonts below that size will not be reliably detected. Abnormally styled fonts may not be clear or consistent.
Note
OCR is not supported for HP UX 11.31+ (Intel Itanium) and Solaris 9+ (Intel x86) operating systems.
Remediation
CipherTrust Intelligent Protection (CIP) solution allows customers to discover and protect their sensitive data. To use this feature DDC needs to work with CipherTrust Transparent Encryption (CTE) and requires a CTE Agent installed alongside a DDC agent on a data store to be monitored. You have to configure a GuardPoint on the data store with which you want to use remediation. For a detailed procedure, refer to the "Managing GuardPoints" topic on the CipherTrust Platform Documentation Portal.
With the help of CTE the security issues found during a scan are encrypted and the risk is thus remediated. The results of this remediation action can then be viewed in the report. For details about remediation information, refer to Remediation Information.
Currently, remediation is only supported on local storage type data stores. Remediation will only work if there is a CTE Agent installed and a GuardPoint configured on a data store to scan. Remediation can be executed as part of the scan or can be also launched for scans already previously run without remediation by clicking the Reclassify option in the overflow menu (see Reclassifying Scans).
Note
Due to a known limitation reclassifying scans is only available for scans run in CM 2.7 and above.
Various remediation actions are possible for the Data Objects that are found containing sensitive information. For more information on the available remediation options, refer to the "CipherTrust Intelligent Protection" documentation in the Thalesdocs portal.
The diagram below illustrates how the components of the remediation solution interact with one another.
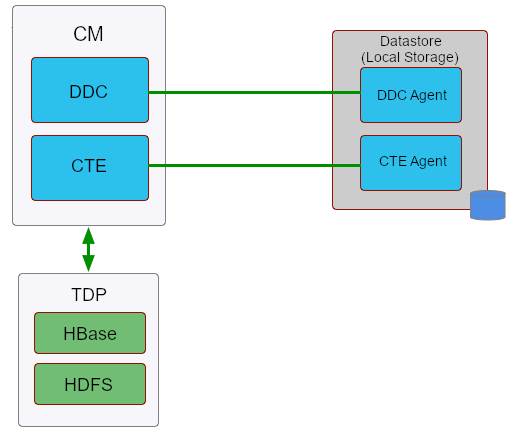
How Does Remediation Work in DDC?
When you try to enable remediation for a target in a scan, DDC has to perform some checks:
Check if there is a CTE agent available:
If it is not, the toggle switch for remediation will become inactive with a message "No CTE Agent" when hovering the mouse over the switch.
If it is available but the CTE Agent or GuardPoint is disabled, the remediation switch shows this message on mouse over: "CTE Agent or GuardPoint disabled".
If first check passes, then an additional check is performed to retrieve the GuardPoint for the scan target that you entered. If no GuardPoint is retrieved then the toggle switch for remediation is blocked and a message "Outside GuardPoint" is displayed if you hover the mouse over the switch.
Finally, after both checks have passed, the enable remediation toggle switch is enabled and you can choose whether to activate remediation for the target path entered or not.
Note
Remediation is a process performed as part of the scan when it is run. Alternatively, remediation can be performed for scans already executed by clicking the "Reclassify" option in the overflow button. This feature is only available for scans run in CM version 2.7 and above. For more information, see Reclassifying Scans.
- After you have saved a scan with at least one target to be remediated, you can later disable remediation. In this case, you will get a warning message indicating "Previous remediation actions will not be reverted". This means, that whatever remediation action triggered as a result of the scan results will not be reverted, but just this scan will not launch new remediation actions even if future scans find sensitive matches in this target.
Scan Filter Usage
This section provides you with a more in-depth information on scan filters with some examples of their usage. For more examples, refer to Scan Filters.
Exclude location by prefix
The Exclude location by prefix filter is used to exclude search locations with paths that begin with a given string. Can be used to exclude entire directory trees. For example, exclude all files and folders in the c:\windows\system32 folder.
API filter name: exclude_prefix
Parameters: Expression - mandatory via UI.
Note
API: Without any expression the default expression is "*" (that is to exclude all prefix, in which case nothing is scanned).
Errors: "Expression field required" inline error if you don't type in any text.
Examples:
With expression "data", the filter takes into account the prefix started by "data" like "dataset.txt" or similar.
You can use the asterisk "*", a wildcard character that matches zero or more characters in a search string, and the question mark "?", a wildcard character that matches exactly one character. ??? matches 3 characters. If placed at the end of an expression, ? also matches zero characters.
- File* - Excludes all files beginning with "File"
- /home/my folder/File* - Excludes all files beginning with "/home/my folder/File"
- /home/my folder/File*2021 - Excludes all files beginning with "/home/my folder/File" + something + "2021" like "/home/my folder/File2021", "/home/my folder/File_2021", "/home/my folder/File 2021.csv"
Considerations: If you use the filter by expression and refers to a table name, the scan will exclude that table or the columns whose name matches with the filter.
Exclude location by suffix
The Exclude location by suffix is used to exclude search locations with paths that end with a given string. For example, entering led.jnl, excludes files and folders such as canceled.jnl, totaled.jnl.
API filter name: exclude_suffix
Parameters: Expression - mandatory via UI.
Note
API: Without any expression, the default expression is "*" (that is to exclude all suffix, in which case nothing is scanned).
Errors: "Expression field required" inline error if you do not type in any text.
Examples:
With an expression "txt", the filter takes into account the suffix ended by "txt" like "dataset.txt" or similar.
We can use the "*"
- txt - Excludes all files ending with "txt"
- *txt - Excludes all files ending with "txt"
- in*txt - Excludes all files ending with "in" + something + "txt" like "information.txt", "in.txt", "data_info.txt"
- data.??? - Excludes all files ending with "data" + 3 characters like "data.txt", "data.doc", but does not exclude "data.go" or "data.docx".
Considerations: If you use the filter by expression and refers to a table name, the scan will exclude that table or the columns whose name matches with the filter.
Exclude locations by expression
The Exclude locations by expression filter is used to exclude search locations by expression. The syntax the of the expressions you can use are as follows:
- ?: A wildcard character that matches exactly one character; ??? matches 3 characters. C:\V??? matches C:\V123, but not C:\V1234 or C:\V1.
- *: A wildcard character that matches zero or more characters in a search string. /directory-name/ matches all files in the directory. /directory-name/.txt matches all txt files in the directory.
API filter name: exclude_expression
Parameters: Expression - mandatory via UI.
Note
API: Without any expression, the default expression is "*" (that is to exclude all expressions, in which case nothing is scanned).
Errors: "Expression field required" inline error if you don't type in any text.
Examples:
- With expression data.txt, the filter excludes files that match exactly with "data.txt" (be careful with the path).
- We can use the "*"
- *data.txt - Excludes files that end by "data.txt" in any path.
- data - Excludes files that match with anything + "data" + anything, like "/home/my dir/data", "/data.txt", "C:
- my folder\data1
- my sensitive file.txt"
- data.txt* - Excludes files that start with "data.txt" in any path.
- *data.??? - Excludes all files ending with anything + "data" + 3 characters like "data.txt", "/home/data.txt", "C:
- data.txt", "data.doc", but does not exclude "data.go" or "data.docx".
Considerations: If you use the filter by expression and refers to a table name, the scan will exclude that table or the columns whose name matches with the filter.
Include locations modified recently
The Include locations modified recently filter is used to include search locations modified within a given number of days from the current date. For example, enter 14 to display files & folders that have been modified not more than 14 days before the current date.
API filter name: include_recent
Parameters: Days from current date - integer number up to 99 - mandatory
Errors: days missing/wrong param for include_recent filter → "message": "Invalid number of days"
Examples: Filter value: 5 → The filter includes files and folders that have been modified not more than 5 days before the current date.
Exclude locations greater than file size (MB)
The Exclude locations greater than file size (MB) filter is used to exclude files that are larger than a given file size (in MB).
API filter name: exclude_max_size
Parameters: MB: integer number equal or greater than 1 MB - mandatory
Errors: size missing/wrong param for exclude_max_size filter - "message": "Invalid max size: " / "message": "Invalid max size: 0"
Examples: Filter value: 15 - Exclude files that are larger than 15 MB
Note
In the case of AWS S3, ".zip files" are treated as folders by the scan agent. Hence, ".zip files" that are larger than the size specified in the exclude_max_size filer are not actually excluded.
Include locations within modification date
Description: Include search locations modified within a given range of dates. Prompts you to select a start date and an end date. Files and folders that fall outside of the range set by the selected start and end date are not scanned.
API filter name: include_date_range
Parameters:
- Start date - mandatory
- End date - mandatory
Errors:
- to_date and from_date missing/wrong param for include_date_range filter - "message": "Invalid start date"
- to_date missing/wrong param for include_date_range filter - "message": "Invalid start date"
- from_date missing/wrong param for include_date_range filter - Be careful! - "message": "Invalid start date"
Examples:
- If you set a date with some text before the format <YYYY-MM-DD>, i.e. "2021-05-21 kjsf" or "2021-05-21 14:23", then only is taken the match "2021-05-21"
- If the to_date param is greater than from_date no error is returned.
Limitations: For datastores like Databases, Exchange Online, G-Mail, etc, it seems that the filter by date works for folder and files, but not for databases or email.
Additional Considerations With Relation to Data Store Types
Databases
Be careful with the expression when you try to exclude some objects like tables or schemes. For example, if you want to exclude a specific table in MSSQL, you can use a filter like mydb:1433/myschema/mytable, taking into account the database, the schema and the table.
In MongoDB if you want to skip one table you have to put an star at the beginning of the table like so:
"contacts"
to take into account the table or if not, to specify the full path:
"sensitive-data:27017/contacts/"
(specifying the database and the port). If you only put "sensitive-data:27017/contacts" the filter does not work. The column filter does not seem to work on MongoDB. This limitation is only applicable to the exclude_expression filter.
Filter Columns in Databases
You can filter out columns in databases by using the "Exclude location by suffix" filter to specify the columns or tables to exclude from the scan.
| Description | Syntax |
|---|---|
| Exclude specific column across all tables in a database. | <column name> Example: To filter out "columnB" for all tables in a database, enter columnB. |
| Exclude specific column from in a particular table. | <table name>/<column name> Example: To filter out "columnB" only for "tableA" in a database, enter tableA/columnB. |
Note
Filtering locations for all Target types use the same syntax. For example, an "Exclude location by suffix" filter for columnB when applied to a database will exclude columns named columnB in the scan. If the same filter is applied to a Linux file system, it will exclude all file paths that end with columnB (e.g. /usr/share/columnB). Use the Apply to field if the global filter only needs to be applied to a specific Target Group or Target.
Database Index or Primary Keys
Certain tables or columns, such as a database index or primary key, cannot be excluded from a scan. If a filter applied to the scan excludes these tables or columns, the scan will ignore the filter.
File Systems
Regarding the "Include locations modified recently" and "Include locations within modification date" filters, both ranges are taken into account. For example:
We have a file edited on 20th August 2021 and another one edited in November 2019. Then we add the filters on 20th August:
- "Include locations modified recently" - 4 Days from the current date,
- "Include locations within modification date" - Start: 15th Oct 2019 - End: 17th Aug 2021.
Then both files are taken into account. Both these filters work with the conjunction of the elements.