Configuring Output Parameters
This section describes the Output Configuration parameters and covers the following topics:
Output Configuration Overview
The output configuration is a section in migration.properties/masking.properties/detokenization.properties file. It contains all the necessary information required for creation of output data file/inserting values in the destination database table. For example, the output data file name and path or the destination database details is passed to Bulk Utility as the parameter in output configuration section of properties file. The configuration section must contain the correct information, in the correct order.
The Output.Sequence parameter in the migration.properties/masking.properties/detokenization.properties file specifies the sequence, of the input columns and tokenized columns, in which they are written to the output file. If a column of input file has to appear in the output file, then its column index needs to be specified in the output sequence. The sequence number can either be positive or negative.
Positive sequence number indicates that the decrypted and/or tokenized value for a column is written to the output file, if the column was decrypted and/or tokenized. While negative sequence number indicates that the original value for a column, from the input file is written to the output file. For any columns that are not decrypted and/or tokenized, the specified sequence number has the same effect.
The source and destination database should have same schema and the sequence of columns should be same with respect to database and file.
Note
Constraints of the destination database that may prevent insertion of plain/tokenized should be dropped before running the bulk utility.
Below is a sample of the Output Configuration section of migration.properties file:
######################
# Output Configuration
# Output.FilePath
# Output.Sequence
######################
#
# Output.FilePath
#
# Specifies full path to the output file
#
Output.FilePath = C:\\Desktop\\migration\\tokenized.csv
#
#Intermediate.FilePath
#
# Specifies the intermediate file path in which the intermediate temporary chunks will be stored
#
# If not specified, then the Output.FilePath will be used as Intermediate.FilePath
#
Intermediate.FilePath =
#
# Output.Sequence
#
# Specifies sequence of the input columns in which they are written to the
# output file. Each column in the input file that has to appear in the
# output file has to have its column index specified in the output sequence.
# For each column in the input file, the sequence number can be either positive
# or negative. Positive sequence number indicates that the decrypted and/or
# tokenized value is written to the output file, if the column was decrypted
# and/or tokenized. Negative sequence number indicates that the original value
# from the input file is written to the output file. For columns that are not
# decrypted and not tokenized (pass-through columns) specifying positive or
# negative number has the same effect.
# Column indexes are separated by , character.
#
Output.Sequence = 0,-1,-2,-3,-4,5,6
Below is a sample of the Output Configuration section of masking.properties file (for DB-to-DB tokenization):
#####################
# Destination Database Configuration for DB-to-DB
# Destination.HostName
# Destination.PortNumber
# Destination.DatabaseType
# Destination.DatabaseName
#####################
Note: Source and destination database tables should have the same table structure.
#
#Destination.HostName
#
#Specifies the IP address of the destination database to which tokens are to be
# written.
Destination.HostName = 10.164.13.192
#
#Destination.PortNumber
#
#Specifies the port number of the destination database.
Destination.PortNumber = 1521
#
#Destination.DatabaseType
#
#Specifies the type of the destination database to connect.
Destination.DatabaseType = Oracle
#
#Destination.DatabaseName
#
#Specifies the destination database name.
Destination.DatabaseName = orcl
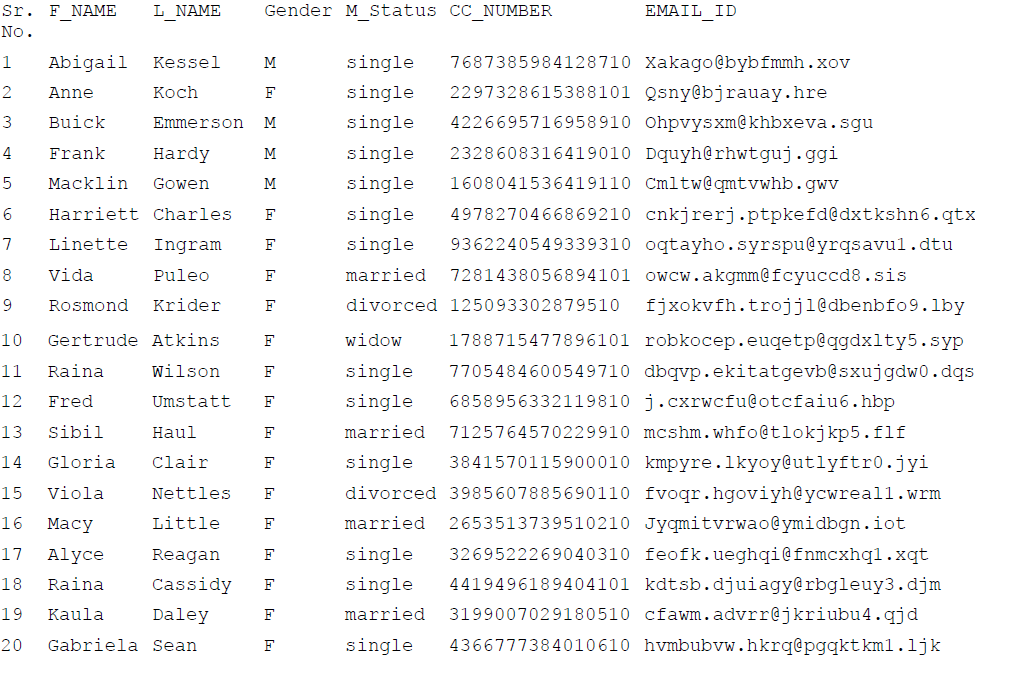
Output Data File
The output data file format (for File-to-File tokenization) is same for both type of input configuration file formats: Delimited and Positional.
The following example shows an output data file:
Sample Output Data File for File-to-File Tokenization
The columns in output file are comma separated.

Sample Destination Database Table for DB-to-DB Tokenization