Tokenization for Positional Type Input File Using Masking.properties File
In this sample, using CT-V Bulk Utility, a positional type data file will be masked using masking.properties file.
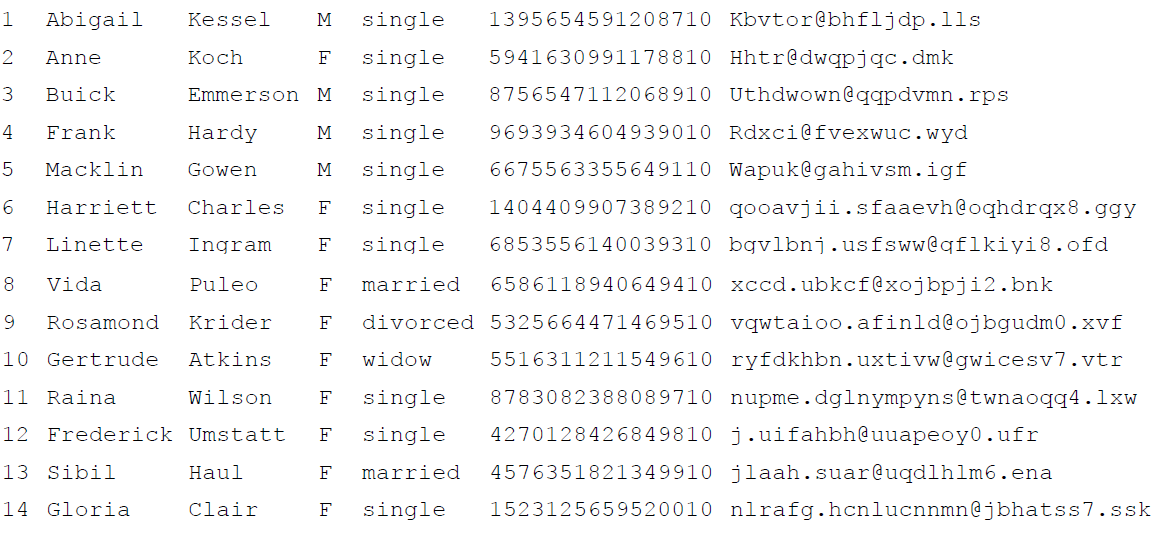
Creating the Input Data File
Below is the data that will be used to populate the customerTable_Positional.csv file:
Setting Parameters for Masking.properties File
Below is the parameters set for positional format input data file:
#####################
# Input Configuration
# Input.FilePath
# Input.Type
#####################
#
Input.FilePath = C:\\Desktop\\masking\\customerTable_Positional.csv
#
Input.Type = Positional
################################
# Positional Input Configuration
# Input.Column0.Start
# Input.Column0.End
# ...
# Input.ColumnN.Start
# Input.ColumnN.End
# Note: For positional input type, a tab will be considered as a single character.
################################
#
Input.Column0.Start = 0
Input.Column1.Start = 3
Input.Column2.Start = 15
Input.Column3.Start = 26
Input.Column4.Start = 28
Input.Column5.Start = 36
Input.Column6.Start = 53
#
#
Input.Column0.End = 2
Input.Column1.End = 13
Input.Column2.End = 25
Input.Column3.End = 27
Input.Column4.End = 36
Input.Column5.End = 52
Input.Column6.End = 83
###########################################
# Tokenization Configuration
# Mask.Column0.TokenFormat
# Mask.Column0.StartToken
# Mask.Column0.LuhnCheck
# Mask.Column0.InputDataLength
# ...
# Mask.ColumnN.TokenFormat
# Mask.ColumnN.StartToken
# Mask.ColumnN.LuhnCheck
# Mask.ColumnN.InputDataLength
############################################
#
Mask.Column5.TokenFormat = LAST_FOUR_TOKEN
Mask.Column6.TokenFormat = EMAIL_ADDRESS_TOKEN
Mask.Column5.StartToken =
Mask.Column6.StartToken =
#
Mask.Column5.LuhnCheck = true
Mask.Column6.LuhnCheck = false
#
Mask.Column5.InputDataLength = true
Mask.Column6.InputDataLength = false
######################
# Output Configuration
# Output.FilePath
# Output.Sequence
######################
#
Output.FilePath = C:\\Desktop\\migration\\tokenized.csv
# Set positive value for columns to be tokenized. For example column 5 and 6 have
# been set positive below, so now only these two columns will be tokenized.
Output.Sequence = 0,-1,-2,-3,-4,5,6
# TokenSeparator
#
# Specify if the tokens are space separated or not.
# Note: This parameter is ignored if Input.Type is set to Delimited.
#
# Valid values
# true
# false
# Note: Default value is set to true.
#
TokenSeparator = true
#
# StreamInputData
#
# Specifies whether the input data is streamed or not.
#
# Valid values
# true
# false
# Note: Default value is set to false.
#
StreamInputData = false
Note: Applicable for only positional type input file. If StreamInputData is set to true, the
TokenSeparator parameter is not considered.
#
# CodePageUsed
#
# Specifies the code page in use.
# Used with EBCDIC character set for ex. use "ibm500" for EBCDIC International
# https://docs.oracle.com/javase/7/docs/api/java/nio/charset/Charset.html
#
CodePageUsed =
Note: If no value is specified, by default, ASCII character set is used.
###############################################################################
# END
###############################################################################
Running CipherTrust Vaulted Tokenization Bulk Utility
Enter the following command to encrypt with CT-V Bulk Utility in a Windows environment:
java -cp SafeNetTokenService-8.12.3.000.jar com.safenet.token.migration.main config-file-path -ftf DSU=NAE_User1 DSP=qwerty12345
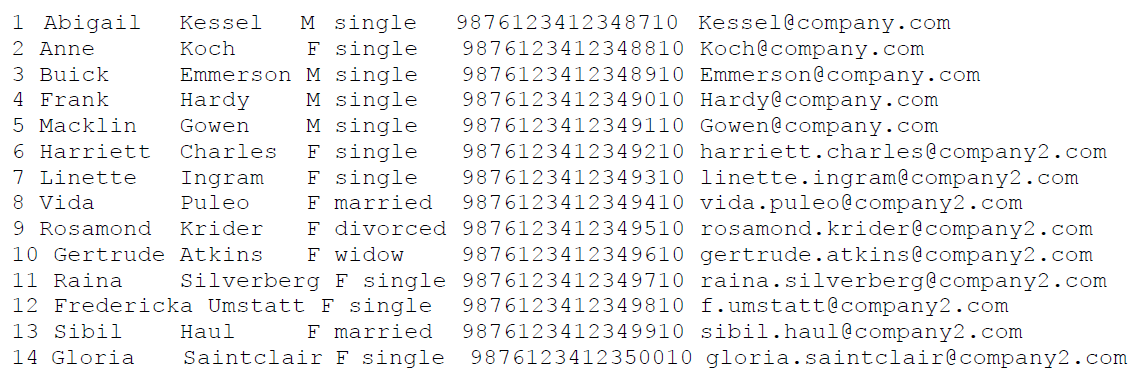
Reviewing the Output File
The output data file is saved at the same path mentioned in the masking.properties file with the same name tokenized.csv. As per the output sequence parameter, only column 5 and 6 are tokenized.
Here is the data from the output file: