Configuring Input Parameters
This section describes the Input Configuration parameters and covers the following topics:
Input Configuration Overview
The input configuration section lists and defines the parameters required to define the input data file and the columns from input data file that needs to be tokenized (migration.properties and masking.properties files) or detokenized (detokenization.properties file). For example, the name and path for the input data file is passed to the CT-V Bulk Utility through the Input File Path and Input Type parameters in the Input Configuration section of migration.properties/detokenization.properties/masking.properties file (for File-to- File tokenization).
Below is a sample of the Input Configuration section of migration.properties/detokenization.properties/masking.properties file (for File-to File tokenization):
#####################
# Input Configuration
# Input.FilePath
# Input.Type
#####################
#
# Input.FilePath
#
# Full path to the input file
#
Input.FilePath = C:\\Desktop\\migration\\customerTable.csv
#
# Input.Type
#
# Format of the input file
#
# Valid values
# Delimited
# Positional
#
Input.Type = Delimited
###############################
# Delimited Input Configuration
# Input.EscapeCharacter
# Input.QuoteCharacter
# Input.ColumnDelimiter
###############################
#
# Input.EscapeCharacter
#
# Specifies a character that is used to 'escape' special characters that
# alter input processing
#
# Note: this parameter is ignored if Input.Type is set to Positional
#
Input.EscapeCharacter = \\
#
# Input.QuoteCharacter
#
# Specifies a character that is used around character sequences that contain
# delimiter characters and are to be treated as a single column value
#
# Note: this parameter is ignored if Input.Type is set to Positional
#
Input.QuoteCharacter = "
#
# Input.ColumnDelimiter
#
# Specifies a character that separates columns in the input file
#
# Note: this parameter is ignored if Input.Type is set to Positional
#
Input.ColumnDelimiter = ,
################################
# Positional Input Configuration
# Input.Column0.Start
# Input.Column0.End
# ...
# Input.ColumnN.Start
# Input.ColumnN.End
################################
#
# Input.ColumnN.Start
#
# Specifies zero-based position where the value starts. The character in the
# specified position is included in the column value. This value must be
# specified for every column in the input file which has to be processed
# or passed-through and included in the output file.
#
# Note: this parameter is ignored if Input.Type is set to Delimited
#
Input.Column0.Start =
#
# Input.ColumnN.End
#
# Specifies zero-based position where the value ends. The character in the
# specified position is included in the column value. This value must be
# specified for every column in the input file which has to be processed
# or passed-through and included in the output file.
#
# Note: this parameter is ignored if Input.Type is set to Delimited
#
Input.Column0.End =
The information required in the input configuration file depends on the input data format. The Input File Path parameter determines the location of the Input Data File and the Input Type parameter determines the format in which data can be provided to the utility which can be positional or delimited.
Note
The structure of the elements in the configuration files is imperative. If the tags are not in the correct order, the session fails.
Input Data File for Delimited Input
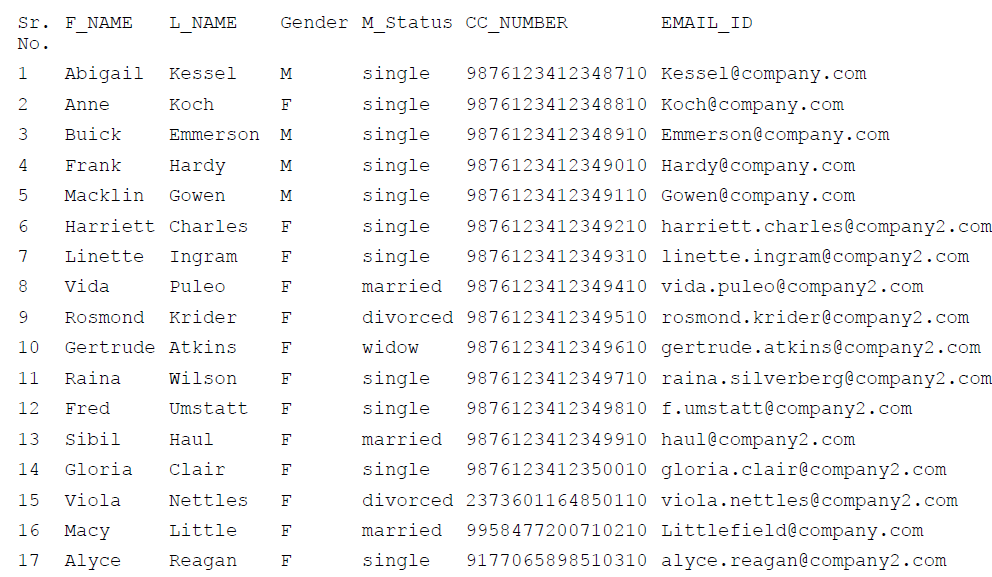
The input data file for delimited input can be in various formats like .csv, .dat, .txt, etc. In a delimited input data file, the columns are separated using a delimiter, which may be a special character say ‘,’.
Below is an input data file containing comma-delimited data with seven columns:

Input Data File for Positional Input
The input data file for positional input can also be in various formats like .csv, .dat, .txt, etc. In a positional input data file, the columns are separated by setting a parameter in the input config file defining the start and end of the column. For positional input type, a tab will be considered as a single character.
The input data file shown below is with positional data:
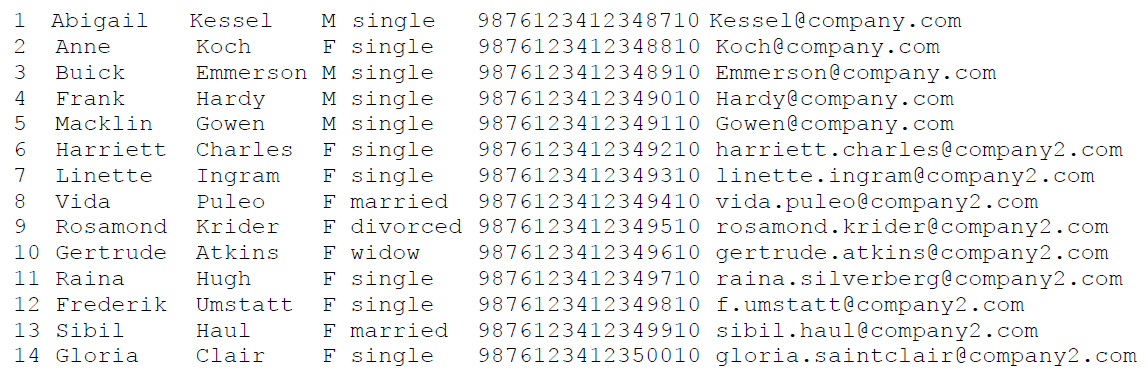
The file has seven columns. The first column begins at position 0 and ends at 2, second column begins at position 3 and ends at position 13, third column begins at position 15 and ends at position 25, fourth column begins at position 26 and ends at position 27, fifth column begins at position 28 and ends at position 36, sixth column begins at position 36 and ends at position 52 and seventh column begins at position 53 and ends at position 83.
Sample Input Configuration File for Stream Data
Input Configuration for DB-to-DB Operation
The input configuration section lists and defines the parameters required to define the source database from which the plaintext values in table needs to be masked.
Note
The DB-to-DB operation is supported only between homogeneous databases.
Below is a sample of the Input Configuration section of masking.properties file (for DB-to-DB tokenization):
###############################
# Source Database Configuration for DB-to-DB
# Source.HostName
# Source.PortNumber
# Source.DatabaseType
# Source.DatabaseName
###############################
Note: Mandatory for DB-to-DB tokenization. Also, name and structure of source and destination
database tables must be same.
#
#Source.HostName
#
#Specifies the IP address of the database server from which, the
#CipherTrust Vaulted TokenizationBulk Utility to read the plain values
# to be masked.
Source.HostName = 10.164.12.170
#
#Source.PortNumber
#
#Specifies the port number of the database server.
Source.PortNumber = 1521
#
#Source.DatabaseType
#
#Specifies the database type to connect.
Source.DatabaseType = Oracle
#
#Source.DatabaseName
#
#Specifies the database name of the server.
Source.DatabaseName = orcl
Sample Source Data Table for DB-to-DB Operation